LLM Research
I’ve been doing quite a bit of research into the LLM landscape recently, and this is a sort of dump of what I’ve learnt. The background section of this post gives context for the rest of it for readers who aren’t that familiar with the tehnology behind LLMs, but in order to include it in a reasonable way I’ve had to make some truly painfully simplified explanations of the sort that make me wince. I’ve tried to include links to far better explanations where possible, so please do follow those if you find yourself wincing too.
Background
LLMs are generative neural networks that use a transformer architecture, state-of-the-art LLMs are trained with unsupervised learning on large corpuses of text scraped from the web, books, and other sources before being fine-tuned with RLHF.
There’s a lot to take on board in that sentence alone, so I’m going to try to explain each part of it below, along with a few extra terms that are important for understanding:
Neural networks
Artificial neural networks (which I’ll just call neural networks from now on) mimic the biological neural networks found in animal brains. They work by creating a graph like the one in Fig 1, each of the circles in the graph is a neuron, each vertical slice of neurons is called a layer. When someone makes a neural network with lots of these layers they say they’re doing deep learning, but that term isn’t too important.
Neural networks were invented in the 50s(!), but they were kind of ahead of their time and no one could really use them to do very much. In 2010 AlexNet, a neural net entry to an OCR competition, blew away its competition. It showed that neural networks could be incredibly powerful as long as you threw enough training data at them, and computers (and GPUs specifically) were now fast enough to make this practical.
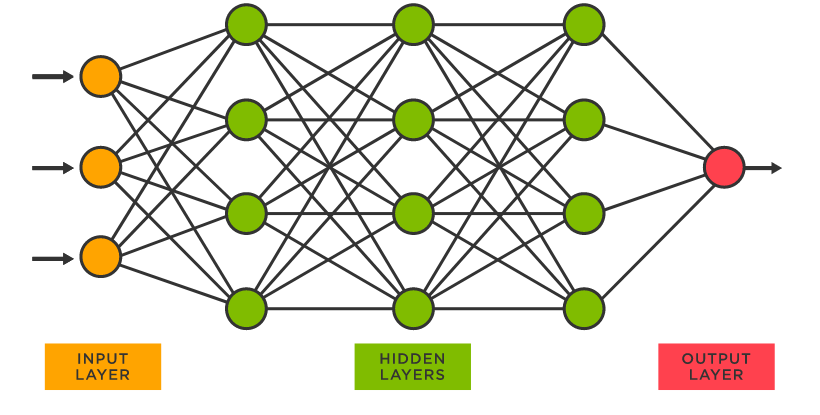
Data is fed into the input layer as floating point numbers, with a number going to each neuron in the input layer. Each neuron in the input layer then feeds its number to each of the neurons in the first hidden layer that it is connected to. Each neuron in the first hidden layer receives numbers from one or more neurons in the input layer, and then does some maths on them to get a number that it passes on to every neuron in the second hidden layer that it’s connected to. The second layer then repeats the process, sending those numbers to the third hidden layer and so on, until the output layer outputs one number.
This is all incredibly abstract, so let’s imagine an example. Say you want to recognise images of handwritten digits. You can do this with a neural net by first normalising the digit images into greyscale images of a standard size, let’s say 28x28 pixels. Now you can represent your image as an array of 784 (28x28) numbers, where each number represents the greyscale depth of a pixel in the image. Now you can make a neural net that has an input layer with 784 neurons, a bunch of hidden layers, and an output layer with 10 neurons, where each neuron in the output layer corresponds to a digit (0-9), and the number the neuron outputs represents the probability that the input image is a picture of that digit. You can then train your network (more on how later) to recognise digits, and, really really remarkably, end up with something that actually works.
If you’re not happy with my Pound Shop explanation (and frankly I might judge you a bit if you are) then I highly recommend Michael Neilsen’s Neural Networks and Deep Learning as a free introduction to… well, you get the picture.
Parameters
In the last section I said the neuron “does some maths”. In this section I’ll continue being vague about that maths, but less so. Each neuron has a set of numbers called weights, one for each of its inputs, and a single number called a bias. When it gets new numbers from its inputs it multiplies each by its corresponding weight, adds them all up, then subtracts its bias from that sum, and then it runs that number through a sigmoid function. This result is what it then passes on to the neurons it’s connected to in the next layer.
We call the weights and biases of a network its parameters, and you can sort of think of the software that the neural network runs. The same neural network can, to an extent, be trained to do all sorts of different tasks. Which means that a company publishing the exact architecture of their neural network doesn’t necessarily do anything to help anyone run it in a useful way. Finding useful parameters can cost millions, or tens of millions of dollars in data collection, cleaning, and training compute.
Parameter count is considered pretty important, generally speaking the more you have the more powerful your model can be. But increasing parameter count increases the cost of compute when both training and running the model. So models will often come in a number of different sizes and have names that indicate the number of parameters they have in billions, like LLaMA 7B, LLaMa 65B, or PaLM 540B(!). OpenAI kind of started a parameter war in the LLM space when they got spectacular results with GPT-3 using 175 billion parameters (which was a lot at the time, and still kind of is), but spending your training compute budget on parameters has been called into question a bit since Deepmind got outsized results with Chinchilla, a relatively small model trained on a lot of data that ended up being both better and cheaper to run than bigger models. This LessWrong post is a really great writeup on the implications of Chinchilla.
Generative Models
Neural networks can, in theory, be used for absolutely anything. Most commonly they’re probably used for classification; performing tasks like detecting spam emails or filtering explicit content on social media. You can think of OCR systems like AlexNet of classifiers too, they take images and classify them as either “a”, “b”, “c” etc.
But generative models are the hot thing now. They include LLMs like the GPT-3/GPT-4, the models behind ChatGPT, and image generating models like DallE-2, Stable Diffusion, and Midjourney. But they’re not limited to these tasks, they can be used to generate music, videos, and even proteins.
Inference
The process of running inputs through a trained model to get outputs. You will often see people talk about the cost of compute in inference vs training.
Architecture
Architecture is, more or less, the shape of the graph that makes up the neural network. You can have a shallow architecture with few layers, or a deep architecture with many. The width of each layer can vary, and so can the way neurons are connected between layers.
The network in Figure 1 is an example of a feed-forward architecture, because each layer simply feeds forward into the next. But there are cycles in the graphs of some architectures, like recurrent neural networks (RNNs), and you can get pretty fancy. Google’s GLaM LLM is an interesting example as it’s basically a bunch of different “expert” LLMs (hence its absolutely enormous parameter-count of 1.2 trillion) behind a gating layer that decides which “expert” layers to hand off a given input to. This saves compute during inference because only 8% of the model’s parameters are activated in a run, which is just as well given its size.
Transformers
Look, I’m not going to pretend to understand how these work. All I know is transformers are an architecture that have taken over as the state of the art since Google published a paper called Attention is All You Need in June 2017. Image generators like Dall-E, Midjourney and Stable Diffusion are transformers, and so are all of the current crop of LLMs. Previously it seems like recurrent neural networks were King, I don’t know how they work either.
Training
Neural networks are (to my knowledge) always trained with backpropagation now. This is a process that, roughly, looks like this:
- Initialise a neural network with random(!) weights and biases
- Take an input for which you know the correct output, run it through the network, and see what output you get
- Check to see how close your network’s output is to the correct output, and tweak your parameters to get it closer (using backpropagation)
- Repeat this process with a different input/output pair, ideally a lot. Billions, or trillions of times if you can stretch to it.
The step where you tweak the parameters is the conceptually hard bit, and how you do that is entirely non-obvious, so backpropagation is a very big deal! If it (or something very similar) didn’t exist, we probably wouldn’t use neural networks.
Supervised Learning
In supervised learning you train a machine learning model (it doesn’t have to be a neural network) on data that has been labelled, which usually means you’ve got human beings to look at an input and create an output for a model to aspire to. This is often called data annotation, and it can mean things like translating text, or drawing boxes around items in an image and labelling them with their name “cow”, “chair” etc. Since complex problems rely on a real mountain of data this can get expensive very quickly, so people try to find clever ways of getting labelled data for free. The first version of Google translate was trained on openly-available documents that had been meticulously translated by the UN for their own purposes. If you can’t offload the cost of training your model onto the UN then you might want to try…
Unsupervised Learning
Unsupervised learning is when you try to find structures, patterns, and/or relationships in a large amount of unlabelled data. It might sound surprising that this works, or can be useful, but it does, and is; and you can use it to do things like find items in purchasing data that are frequently bought together, or train language models that trick people into thinking they’re sentient.
As a parallel to the Google translate supervised learning example in the previous section, in 2018 Facebook announced they’d successfully created a translation pipeline that was trained with unsupervised learning alone. To do this they embedded words in a many-dimensional space, based on how closely they tend to appear near other words. They do this for a lot of languages, and then rotate the word-spaces so that they are aligned with each other as shown in Figure 2. After that, translating a word from language A to language B just means finding the word in language A’s space, then finding the word in language B’s space that’s nearest to it. For a better understanding of how this works, and of how they fix the garbled grammar that word-by-word translation inevitably produces I really recommend reading the Facebook announcement post.

Excitingly, this approach doesn’t just save Facebook money on data labelling, it also allows them to translate languages for which very little translation data is available. There’s even a project that is trying to use this sort of approach to translate whale song (on which we have a surprising amount of data) into human language. And they’ve called it the Cetacean Translation Initiative , or CETI for short. That’s a play on SETI, the Search for ExtraTerrestrial Intelligence, and for my money the best name of any project in all of machine learning.
Tokens
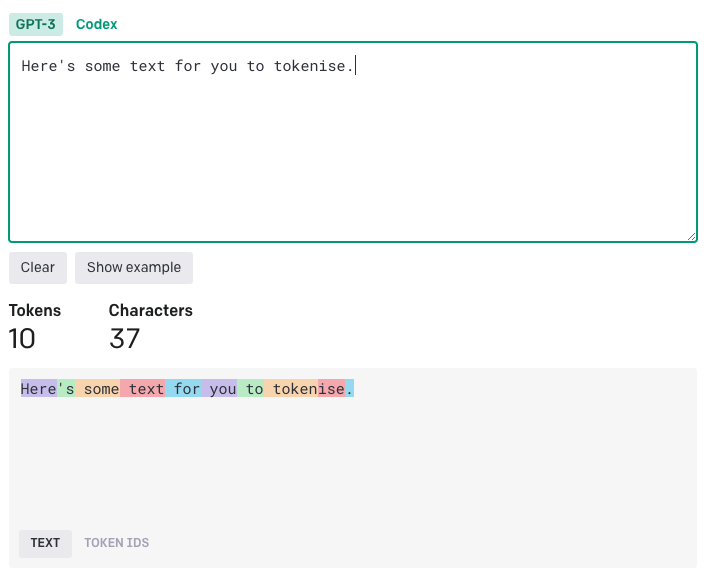
LLMs work by trying to predict the next token given a string of tokens, where a token is neither necessarily a character nor a word, but a short string of characters. Each token is mapped to an integer for the model to work with, and tokens are chosen for their ability to represent language in as few tokens as possible for a given token set-size. Figure 3 shows an example of a string that has been tokenised with OpenAI’s tokenisation tool.
Pre-Training
I’m not sure how much people talk about pre-training for other types of machine learning, but in the context of LLMs pre-training usually means using a giant corpus of unlabelled data and unsupervised learning to train a model to predict the next token in a piece of text. This is where models learn their spelling and grammar, and build up a model of the world that’s useful for predicting the next character accurately.
Fine-Tuning
Once a model has been pre-trained, it can be fine-tuned you can train it for more specific tasks (like writing code, or not being racist) with fine tuning. In this step humans produce input prompts, and output responses which are used to train the model with supervised learning.
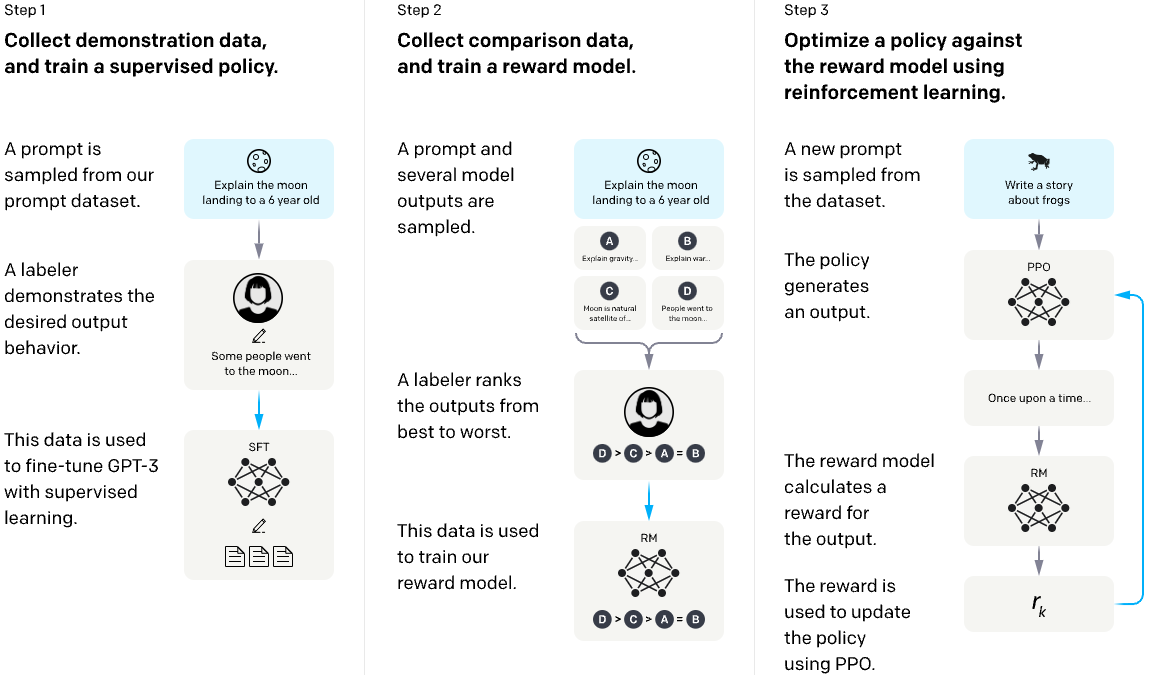
Reinforcement Learning With Human Feedback (RLHF)
In this step a pre-trained and fine-tuned model is used to generate multiple responses, which are ranked by a human labeller. This data is then used to train a model that ranks responses, and the response-ranker is used to give the model feedback in another training run. Fig. 4 is a serious diagram explaining fine-tuning and RLHF process from an interesting post on alignment. Fig. 5 is a meme post that, in some ways, explains the process even better.
Few-Shot Learning
Also often called n-shot learning, is the part that makes AI researchers who don’t work at OpenAI very sad. It turns out that once you’ve trained a big enough, generalist LLM you can often solve classes of problem without training a model specifically for that problem, and without even fine-tuning for it. Instead you can just reframe your problem as a text-completion problem. Like this:
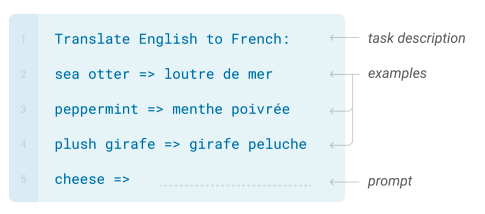
Or even like this:

In fact if your model is good enough, as ChatGPT often is, you might even be able to solve your problems with…
Zero-Shot Learning
This is where you’re able to get results from an LLM with a prompt that doesn’t even contain any examples. Which is good both because it’s easier, and because LLMs have context windows into which their prompts and answers have to fit, and examples eat up precious tokens in that context window.
Available AI Models
https://nat.dev/ is an LLM playground made by former GitHub CEO Nat Friedman, and an amazing resource for trying out and comparing current LLMs. In an astounding act of loosely-targeted generosity Nat used to foot the (presumably hefty) bill for this, but it’s now paid. Though still cheap. I recommend forking out.
Anthropic Claude
Anthropic is a Google-backed AI startup founded by former OpenAI employees in 2021, and their LLM is called Claude. It’s comes in Claude, and Claude Instant flavours, which are only available through integrations in the apps of their partners, including Notion, Quora, and DuckDuckGo. You can find out more from their announcement post.
Meta LLaMA
This model was trained to be Chinchilla-optimal, i.e. it was trained with a lot of training data relative to model size. It was also trained exclusively on publicly available data, to prove that one doesn’t need to buy access to private data in order to train a powerful model. It comes in 7B, 13B, 33B, and 65B flavours; according to the announcement post 13B outperforms GPT-3, while 65B manages to outperform the eigth-times-bigger PaLM-540B!
Meta didn’t make LLaMA’s parameters public, but they did make it available to researchers under strict terms. Some brave soul ignored those terms and made a torrent of the parameters public, and all sorts of people have been having a field day ever since. Simon Willison has a really great writeup of all the cool things people have built off of the back of this, but sadly it isn’t at all commercialisable for obvious reasons.
Meta OPT
A 175B parameter model, open sourced by Meta for the research community. This is cool but the licence is noncommercial, so you can’t use it for much other than tinkering. Announcement.
OpenAI GPT-3.5
Available through the OpenAI API in a number of different flavours
gpt-3.5-turbooptimised for chat, ~4,000 max tokens, API calls can include a “system message” to tell the assistant what behaviour you’d like it to exhibit.text-davinci-003can be used for text completion, less powerful than its chat-optimised brother, and yet 10x more expensive. It can, however, be fine tuned if you need to do that sort of thing.code-davinci-002optimised for code completion and can handle ~8,000 tokens.
For even more basic tasks older models (curie , ada, and babbage) are still available, and they can also be fine-tuned.
OpenAI GPT-4
This is the best of the LLMs as far as I can tell. OpenAI haven’t said how many parameters it has, how many tokens they used in pre-training, where they got the tokens from, or how they did RLHF. They’re keeping quiet about all of this in part out of a fear that models like this might wipe out the human race one day (really!).
More parochially, you can be awed by GPT-4 in ChatGPT for just $20/month, but the API is currently in limited beta. There are ChatGPT plugins with a pretty incredible API in limited alpha. You pretty much just declare a manifest with an OpenAPI spec for the endpoints you want ChatGPT to use, and a natural language description of what your app does, and ChatGPT works out the rest.
Cerebras-GPT
Cerebras—a company (sort of) famous for making an ML-optimised processor so massive it’s pretty much just a squared off silicon wafer—have made, and open-sourced this one to show off their massive chip. It comes in a few sizes: 111M, 256M, 590M, 1.3B, 2.7B, 6.7B, and 13B parameters; and they should all be pretty good for their size as they’re trained for optimal compute use like Chinchilla and LLaMA, though I haven’t been able to try any of them yet so can’t say much more about their real-world performance. The announcement post is here.
GPT4All
Although the repo claims this is MIT licensed, I don’t think it’s any good for commercial use as it’s based on LLaMA. According to the technical report it’s essentially LLaMA that has been fine-tuned using prompt-response pairs collected from ChatGPT, so they’re kind of freeloading off the hard work OpenAI did fine-tuning and RLHFing their model.
EleutherAI GPT-NeoX
At 20B parameters I believe this is the biggest of the openly available models, available on Hugging Face. It’s trained on the ominously-named Pile, a diverse dataset for training open source models. Having tried it on nat.dev it seems… unwieldy, I suspect this might be because it’s only a pre-trained model without fine-tuning or RLHF. I’d say it’s a fixer-upper, but I don’t know how good it can actually get.
EleutherAI Pythia
A set of open source models that are mostly designed to enable research around LLMs.
The Future
Looking at this landscape it kind of looks like if you want to do something commercial right now, and you can’t train your own model, or strike a deal with a company that already has then you pretty much have to use OpenAI’s API.
But I doubt this situation will last for very long. If you already have the data (which is admittedly a big if) there’s reason to believe that a training run for a GPT-3-equivalent model might cost as little as $85,000! And GPT4ALL shows you can leverage GPT-3.5 to get fine-tuning data for very little money: their paper claims they spent just $500 on OpenAI API calls, and a further $800 on compute for training!
I don’t think anyone can (currently) get a ChatGPT-equivalent model for $86,500 all in. ML programmers aren’t free, and you might not be able to get away with doing just one training run, but the overheads don’t look anywhere near as expensive as they once did, and they might already be within reach of a lot of teams. When it’s as available as this I doubt we’ll have to live without good out-of-the-box, open source alternatives to ChatGPT for long.